



Questions on Introduction to Biostatistics 2020 Assessment 3 Answer

Answer
| Biostatistics 2020 |
Question 1
(a) P(t > 2.31) (for the t distribution on 18 degrees of freedom)
Two-tailed p-value = 0.0330
Hence, one-tailed p = 0.0165 which is statistically significant.
(b) P(t >-1.8727) (for t on 5 df)
Two-tailed p-value = 0.1200
Hence, one-tailed p = 0.0600 which is statistically not significant.
(c) P(t < -1.7247) (for t on 20 df)
Two-tailed p-value = 0.1000
Hence, one-tailed p = 0.0500 which is statistically significant.
- P(x2 > 6.68) (arising from a test of association on a 2x2 contingency table)
Df=(2-1)(2-1) = 1
Using distribution table, at df=1, the range containing 6.68 is given by 6.635 and 7.879. Hence, range for p-value is 0.01 < p-value < 0.005
- P(x2 > 9.50) (arising from a test of association on a 4x3 contingency table)
Df=(4-1)(3-1) = 6
Using distribution table, at df=6, the range containing 9.50 is given by 2.204 and 10.645. Hence, range for p-value is 0.90 < p-value < 0.10
Question 2
(a)
| Before | After | Differences | |
| N | 24 | 24 | |
| Mean | 30.07 | 27.26 | 2.81 |
| SD | 6.10 | 5.20 | 7.10 |
α = 0.05
The null and alternative hypothesis can be stated as:
H0: µb = µa
H1: µb ≠ µa
We will use a two-tailed test. Also, the samples are dependent because the tinnitus patients were tested before any medication and then after taking three tablets a day (each containing 50mg of Ginkgo biloba) over a 12 week period.
Hence, we will use t-test for dependent means:
SE = √(sd2/n) = √7.102/24 = √2.1004 = 1.4493
t-stat = (µd – d)/SE = (2.81-0)/1.4493 = 1.9389
df = n-1 = 24-1 = 23
Using T.DIST.2T (1.9389, 23) = 0.0649
Hence, P(t23 > 1.9389) = 0.0649
At significance level of 0.05, p-value of 0.0649 is greater than the significance level. Hence, we don’t have significant statistical evidence to reject the null hypothesis.
(b)
We can conclude that at the significance level of 0.05, we do not have sufficient statistical evidence to conclude that there is difference in mean score before and after treatment. Hence, we can say that there is no difference in in mean score before and after treatment.
Question 3
(a)
| Intervention | Control | ||
| N | 415 | 414 | |
| Mean | 0.56 | 0.43 | |
| SD | 0.87 | 0.73 | |
α = 0.05
The null and alternative hypothesis can be stated as:
H0: µI = µC
H1: µI ≠ µC
We will use a two-tailed test. Also, the samples are independent as the two groups control and intervention are separate. Control group is getting standard care while intervention group is getting two home visits by a pharmacist within two weeks and eight weeks of discharge to educate and aid patients with their medications.
Hence, we will use t-test for independent means:
Pooled SD = √((nI-1)sI2+(nC-1)sC2)/ (nI + nC +2)
= √(415-1)0.872 + (414-1)0.732/(415+414+2)
= √(313.36+220.09)/831
= √0.6419
= 0.8012
SE = pooled SD x √(1/nI) + (1/nC)
= 0.8012 x √1/415 + 1.414
= 0.8012 x √(0.00241+0.002415)
= 0.8012 x 0.069463
SE = 0.0557
t-stat = (µI – µC)/SE = (0.56-0.43)/0.0557 = 0.13/0.0557 = 2.3359
df = nI+ nC -2 = 415+414-2 = 827
Using T.DIST.2T (2.3359, 827) = 0.0197
Hence, P(t827 > 2.3359) = 0.0197
At significance level of 0.05, p-value of 0.0197 is less than the significance level. Hence, we have significant statistical evidence to reject the null hypothesis.
(b)
We can conclude that at the significance level of 0.05, we have sufficient statistical evidence to conclude that there is difference in (population) average number of re-admissions for participants randomised to the intervention and (population) average number of re-admissions for participants randomised to the control.
(c)
The test in part (a) above was a two tailed test. In this case, if there is a one-tailed test, entire significance alpha of 0.05 will be in one tail instead of being divided in two tails as in (a) above.
A one-tailed test will change null and alternative hypothesis as follows:
H0: µI > µC
H1: µI not > µC
Question 4
(a)
| Death Penalty | No Death Penalty | Total | |
| Caucasian | 53 | 430 | 483 |
| African American | 15 | 176 | 191 |
| Total | 68 | 606 | 674 |
α = 0.05
The total sample size is 674 with two variables: ethnicity (Caucasian or African-American) and death penalty (yes or no).
The null and alternative hypothesis can be stated as:
H0: In the population, there is no association between ethnicity and death penalty sentence.
H1: In the population, there is some association between ethnicity and death penalty sentence.
We will use chi-squared test for association.
Expected value table is as follows:
| Death Penalty | No Death Penalty | Total | |
| Caucasian | 53(48.73)[0.37] | 430(434.27)[0.04] | 483 |
| African American | 15(19.27)[0.95] | 176(171.73)[0.11] | 191 |
| Total | 68 | 606 | 674 |
Expected value = row total*column total/grand total (presented in brackets in above table)
t-stat is calculated as c2 = Ʃk [(oi-ei)/ei] (presented in square brackets above. When sum totalled, it reveals t-stat)
t-stat = 1.4685
p-value = 0.22558
At significance level of 0.05, p-value is greater than 0.05 indicating that we do not have sufficient statistical evidence to reject null hypothesis. Hence, we conclude that in the population, there is no association between ethnicity and death penalty sentence.
(b)
| Death Penalty | No Death Penalty | Total | |
| Caucasian | 53 | 414 | 467 |
| African American | 11 | 37 | 48 |
| Total | 64 | 451 | 515 |
α = 0.05
The total sample size is 515 with two variables: ethnicity of defendant (Caucasian or African-American) and death penalty (yes or no).
The null and alternative hypothesis can be stated as:
H0: In the population, there is no association between Caucasian victim’s murderer’s ethnicity and death penalty sentence.
H1: In the population, there is some association between Caucasian victim’s murderer’s ethnicity and death penalty sentence.
We will use chi-squared test for association.
Expected value table is as follows:
| Death Penalty | No Death Penalty | Total | |
| Caucasian | 53(58.03)[0.44] | 414(408.97)[0.06] | 467 |
| African American | 11(5.97)[4.25] | 37(42.03)[0.60] | 48 |
| Total | 64 | 451 | 515 |
Expected value = row total*column total/grand total (presented in brackets in above table)
t-stat is calculated as c2 = Ʃk [(oi-ei)/ei] (presented in square brackets above. When sum totalled, it reveals t-stat)
t-stat = 5.3518
p-value = 0.020701
At significance level of 0.05, p-value is less than 0.05 indicating that we have sufficient statistical evidence to reject null hypothesis. Hence, we conclude that in the population, there is some association between Caucasian victim’s murderer’s ethnicity and death penalty sentence.
(c)
| Death Penalty | No Death Penalty | Total | |
| Caucasian | 0 | 16 | 16 |
| African American | 4 | 139 | 143 |
| Total | 4 | 155 | 159 |
α = 0.05
The total sample size is 159 with two variables: ethnicity of defendant (Caucasian or African-American) and death penalty (yes or no).
The null and alternative hypothesis can be stated as:
H0: In the population, there is no association between African-American victim’s murderer’s ethnicity and death penalty sentence.
H1: In the population, there is some association between African-American victim’s murderer’s ethnicity and death penalty sentence.
We will use chi-squared test for association.
Expected value table is as follows:
| Death Penalty | No Death Penalty | Total | |
| Caucasian | 0(0.40)[0.40] | 16(15.60)[0.010] | 16 |
| African American | 4(3.60)[0.045] | 139(139.40)[0.001] | 143 |
| Total | 4 | 155 | 159 |
Expected value = row total*column total/grand total (presented in brackets in above table)
t-stat is calculated as c = Ʃk [(oi-ei) 2/ei] (presented in square brackets above. When sum totalled, it reveals t-stat)
t-stat = 0.4591
p-value = 0.4980
At significance level of 0.05, p-value is higher than 0.05 indicating that we don’t have sufficient statistical evidence to reject null hypothesis. Hence, we conclude that in the population, there is no association between African-American victim’s murderer’s ethnicity and death penalty sentence.
(d)
At significance level of 0.05, we found that in the population:
- There is no association between ethnicity and death penalty sentence.
- There is some association between Caucasian victim’s murderer’s ethnicity and death penalty sentence.
- There is no association between African-American victim’s murderer’s ethnicity and death penalty sentence.
Hence, conclusively, it could only be found that in case of Caucasian murder victims, there is some association between death penalty sentence and the ethnicity; that is whether the defendant was African-American or Caucasian. We could not conclude similar association in case of African-American murder victims.
Question 5
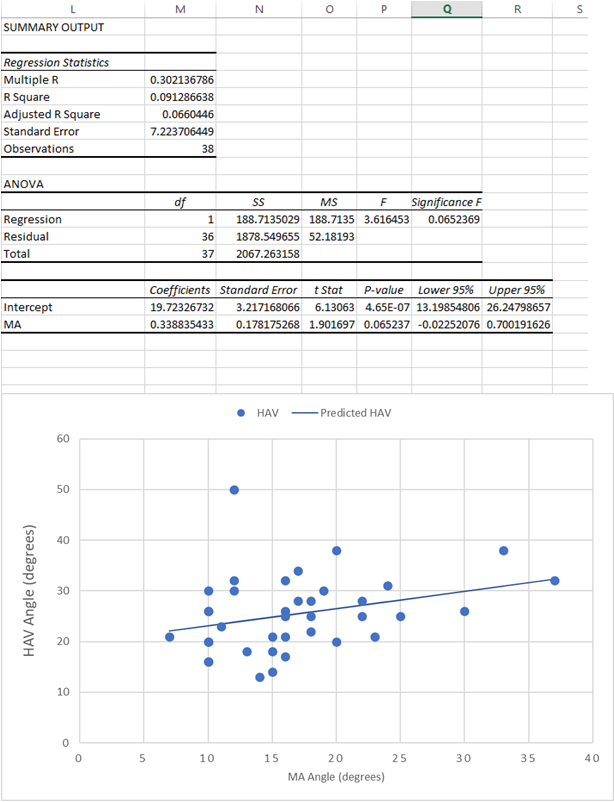
(a)
The regressed equation is:
Y = 19.72+0.34x where y is severity of HAV and x is severity of MA.
The regression output indicates value of r at 0.30 and adjusted R2 at 0.07 which indicates that there is very weak positive correlation between the factors, MA degree and HAV degree.
The p-value for model as well as p-values for coefficients was also higher than 0.05 indicating that model is not a very good fit.
The scatter plot also indicates weak concentration which is range-bound except for a few outliers.
The residual plot indicates a weak wave-like pattern around x-axis which may indicate that linear regression equation is not appropriate and maybe second order equation will be a better fit.
(b)
The slope of the regression line is given by coefficient of MA, that is 0.34. The standard error is 0.1782. We also see that n = 38. Hence, df = 36.
90% CI can be calculated as: 0.34+- t-statc(0.1782)
t-stat is calculated at 36 degrees of freedom and 0.05 tail at either end. From table, this is t = 1.6883
90%CI = 0.34+- (1.6883)(0.1782) = 0.34+-0.30 = 0.64 and 0.04.
Hence, 90% CI ranges from 0.04 to 0.64
(c)
The regressed equation is: Y = 19.72+0.34x where y is severity of HAV and x is severity of MA.
Hence, when x = 30, y = 19.72+0.34(30) = 29.92
Hence, when x = 5, y = 19.72+0.34(5) = 21.42
Despite large change in x-variable, y-variable changes slightly which may lead to questions about the accuracy of the prediction.

Customer Testimonials


