



HI6007 Statistics for Business Decisions Assignment: Tutorial Questions 2 Answer

Answer
Q2a)
Total patients (n) = 400
Referred by local hospital (x) = 80
Proportion of those referred by local hospital p = x/n = 80/400 = 0.2
α = 0.5
CI = p ± z score (√p (1-p) / n)
CI = 0.2 ± 1.96 (√0.2 (1-0.2) / 400)
CI = 0.2 ± 1.96 (√0.2*0.8 / 400)
CI = 0.2 ± 1.96 (0.02)
CI = 0.2 ± 0.0392
CI = 0.2392 and 0.1608 or 16.08% to 23.92% of total patients are expected to be refereed by local hospital at 95% CI.
Q2b)
For calculating sample size:
n = z2 x p(1-p)/e2
= 1.962 x 0.2(1-0.2)/0.042
= 3.8416 x 0.2(0.8)/0.0016
= 384.16 or 385
Hence, a sample size of 385 is required to estimate the proportion of all hospital referrals with a margin of error of 0.04 at 95% CI.
Week 8 Q1
Population Mean Salary = $48,400
Sample size = 100, sample mean = $50,000, population SD = $8,000
a) Hypothesis:
H0: µ = 48,000
H1: µ > 48,000
b) One-sample z-test will be used:
z = (ẍ - µ) / (σ/√n)
c) Typically, a significance level of 0.1, 0.05 or 0.01 is used to compare p-value and see whether there is statistical evidence to reject the null hypothesis. Hence, we assume a significance level of α = 0.05.
d)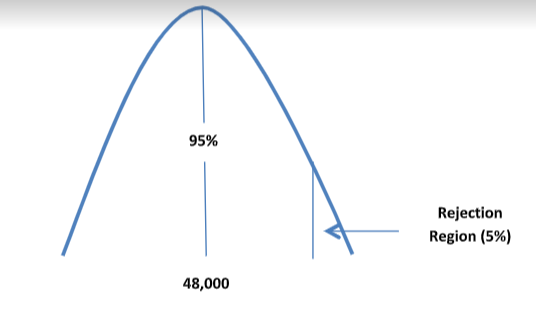
e) Z score is calculated as:
z= (50,000-48,000)/(8000/√100)
z = 2,000/800
z = 2.5
The corresponding p-value at significance level of 0.05 is 0.00621
f) The p-value of 0.00621 is less than the significance level of 0.05 indicating that the result is significant. Hence, we have sufficient statistical evidence to reject the null hypothesis. Hence, we can conclude that there has been a significant increase in the starting salaries.
Week 9 Q3)
a) Hypothesis:
H0: µ1 = µ2 = µ3
H1: At least one mean is different
b) For ANOVA, if F value is greater than F-critical value, then null hypothesis can be rejected. Also, if p-value is less than the significance level of 0.05, then null hypothesis can be rejected.
c) The given data was used to run ANOVA test in excel:
| Anova: Single Factor | ||||||
| SUMMARY | ||||||
| Groups | Count | Sum | Average | Variance | ||
| Process 1 | 4 | 120 | 30 | 4.666667 | ||
| Process 2 | 4 | 136 | 34 | 11.33333 | ||
| Process 3 | 4 | 128 | 32 | 13.33333 | ||
| ANOVA | ||||||
| Source of Variation | SS | df | MS | F | P-value | F crit |
| Between Groups | 32 | 2 | 16 | 1.636364 | 0.24766 | 4.256495 |
| Within Groups | 88 | 9 | 9.777778 | |||
| Total | 120 | 11 | ||||
d) F-value 1.6364 < F critical 4.2565. Also, p-value 0.2477 > significance level of 0.05. Both the results indicate that we do not have sufficient evidence to reject the null hypothesis. Hence, we conclude that there is no significant difference between the mean hourly quantities produced in the three processes.
Week 10 Q2)
a) The estimated regression line is:
y = 45.2159 + 5.3265 x
Where:
- y is wealth in ‘000 dollars
- x is age in years.
The slope coefficient is the coefficient for independent variable x. In this case, it is 5.3265. This coefficient indicates the amount of change in y for a unit change in x.
b) We know that y = 45.2159 + 5.3265 x
Hence, when x=50:
y = 45.2159 + 5.3265 (50)
y = 45.2159 + 266.325
y = 311.5409
Hence, a 50 year old person is expected to have a wealth of $311,540.9
c) The coefficient of determination is also known as R2 and indicates the proportion of variance in the dependent variable (y) that can be explained through independent variable (x). Hence, the amount of change in y that can be attributed to x is coefficient of determination. The value varies from 0 to 1 and higher value indicates a good fit as large proportion of change is being explained by the dependent variable. In this case, R2 is 0.91146 or91.146% of change in y can be explained by variable x. This means that the model is a good fit as a very large proportion of variance in wealth is attributed to the dependent variable, age.
d)
i) Hypothesis:
H0: There is no relationship between x and y (slope β = 0)
H1: There is some relationship between x and y (slope β > 0)
ii) t score = (β-0)/SE
iii) The level of significance is 0.1 as given.
iv) If p-value is less than the significance level of 0.1, it indicates that the model is a good fit.
v) z score = (β-0)/SE
= 5.3265-0/0.6777
t score = 7.8597
df = n-1 = 8-1 = 7
Corresponding p-value at df=7 is 0.000051
vi)Since p-value 0.000051 is less than the assumed significance level of α=0.1, we can reject the null hypothesis. Hence, we can conclude that the slope of the regression line is greater than 0 or, there is a positive linear relationship between the variables y and x.
Week 11 Q3)
a) y = 0.0136 + 0.7992 x1 + 0.2280 x2 -0.5796 x3
b)Coefficient of determination R2 = 1-(SSres/SStot)
= 1 – (2.6218/(2.6218+45.9634)
= 1- 0.053963
R2 = 0.946037
c. Regression df = 3
Error df = 11
Total df = 14
n = 15
SSR = 45.9634
SSE = 2.6218
MSE = SSE/error df = 2.6218/11 = 0.238345
MSR = SSR/regression df = 45.9634/3 = 15.32113
F-ratio = MSR/MSE = 64.28121
Significance F is 0.00000029
At sig level of 0.05, significance F is lower than 0.05 indicating that y is significantly related to the independent variables.
d)
t-stat = Coefficient/SE
The corresponding p-value has been calculated at significance level of 0.05 and a two tailed test was used with df = 14
p-value of 0.5388 > significance level of 0.05 indicating that y is not significantly related to x3.

Customer Testimonials


